|
Технологии
баз данных |
ЛЕКЦИИ
Разработчик: доц. Бородина А.И.
1. Трехуровневая модель организации баз данных
2. Иерархические и сетевые модели данных
4.
Постреляционная, многомерная, объектно-ориентированная
и объектно-реляционная модели данных
&
4.
Постреляционная, многомерная
и объектно-ориентированная
модели данных
4.1. Постреляционная модель
Стройность и мощность реляционных моделей сделали их доминирующими в среде баз данных. Но постоянное усложнение данных позволило выявить ряд неудобств, возникающих при работе с реляционными базами:
· Реляционные системы ограничены в структурах представления данных, так как все данные хранятся в них в виде отношений, состоящих из простых атрибутов. Классическая реляционная модель предполагает неделимость данных, хранящихся в полях таблицы, то есть информация в таблице должна быть представлена в первой нормальной форме. Однако на практике иногда возникают ситуации, когда такое ограничение снижает эффективность работы с базой.
· Данные в реляционной системе пассивны, и для описания их поведения требуется создавать прикладные программы.
· Возможности реляционных баз данных недостаточны в тех случаях, когда объекты данных сложны, например: географические информационные системы, мультимедийные базы, базы с проектной документацией и др.
Все эти требования можно реализовать с помощью реляционных методов, но в результате получается не очень естественное представление требований пользователя.
Постреляционная модель является расширением реляционной модели. Она снимает ограничение неделимости данных, допуская многозначные поля, значения которых состоят из подзначений, и набор значений воспринимается как самостоятельная таблица, встроенная в главную таблицу.
Сопоставим реляционную и постреляционную модели данных на примере. В таблицах 7 и 8 отражена поставка товара в реляционной базе, а в таблице 9 – в постреляционной. Как видно из приведенного примера, в постреляционной базе данные хранятся более компактно, и не требуется выполнять операции связи двух таблиц. Такое хранение обеспечивает высокую наглядность представления данных и повышение эффективности их обработки.
Таблица 7
|
Номер накладной |
Код покупателя |
|
21 |
3241 |
|
18 |
4075 |
|
43 |
2459 |
Таблица 8
|
Номер накладной |
Наименование товара |
Количество |
|
21 |
Соль |
5 |
|
21 |
Сыр |
7 |
|
18 |
Мед |
3 |
|
43 |
Сок |
10 |
|
43 |
Рыба |
20 |
|
43 |
Мясо |
30 |
Таблица 9
|
Номер накладной |
Код покупателя |
Наименование товара |
Количество |
|
21 |
3241 |
Соль Сыр |
5 7 |
|
18 |
4075 |
Мед |
3 |
|
43 |
2459 |
Сок Рыба Мясо |
10 20 30 |
Спецификой постреляционной модели является то, что она поддерживает множественные группы, называемые ассоциированными множественными полями, а совокупность объединенных множественных полей называется ассоциацией, например, в постреляционной модели может присутствовать множественное поле Выпуск, состоящее из полей, указывающих выпуск по кварталам года. В постреляционной модели не накладываются требования на длину и количество полей в записях, что делает структуру таблиц более наглядной.
Таким образом, основным достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц в виде одной постреляционной таблицы. А недостатком является сложность обеспечения целостности и непротиворечивости данных, хранимых в ней.
Постреляционная модель данных реализована в СУБД uniVers, Bubba и Dasdb.
4.2. Многомерная модель
Одновременно с реляционной моделью данных появилась многомерная модель. Однако хоть идеи многомерной модели возникли одновременно с реляционной, но в ту пору практической реализации таких моделей не было. И лишь в 90-х годах ХХ века к ним стал проявляться интерес. Это было вызвано появлением статьи Э. Кодда, в которой он сформулировал 12 требований к системам класса OLAP (Online Analytical Processing – оперативная аналитическая обработка), связанных с возможностью представления и обработки многомерных массивов.
Информация в многомерной модели представляется в виде многомерных массивов, называемых гиперкубами. В одной базе данных, построенной на многомерной модели, может храниться множество таких кубов, на основе которых можно проводить совместный анализ показателей. Конечный пользователь в качестве внешней модели данных получает для анализа определенные срезы или проекции кубов, представляемые в виде обычных двумерных таблиц или графиков.
Развитию многомерных моделей способствовало и то, что широко распространенные реляционные модели и соответствующим образом организованные базы данных хорошо подходили для оперативной, то есть транзакционной обработки данных. В случае же аналитической обработки, то есть поддержки принятия решений реляционные системы не давали желаемого результата. А многомерные базы данных хорошо обслуживают именно аналитическую обработку данных и обычно являются узко специализированными. Они обеспечивают более быстрый поиск и чтение данных по сравнению с реляционными моделями, а также избавляют от необходимости многократного связывания таблиц. Среднее время ответа у них на сложный вопрос в десятки раз меньше, чем при использовании реляционной модели.
Основными понятиями для многомерной модели являются: агрегируемость, историчность, прогнозируемость.
Агрегируемость данных означает рассмотрение и возможность анализа данных на разных уровнях обобщения: для пользователя, аналитика, руководителя. Историчность данных обозначает привязку их ко времени и высокий уровень неизменности (статичности) данных и их взаимосвязей. Временная привязка позволяет выполнять запросы, имеющие значения даты и времени. А статичность – использовать специализированные методы загрузки, хранения, выборки. Прогнозируемость данных предполагает задание функций прогнозирования и применение их к различным временным интервалам.
Многомерность модели данных – это, прежде всего, многомерное логическое представление структуры данных при их описании и в операциях манипулирования ими, а не многомерность их визуализации. По сравнению с реляционной моделью многомерная организация данных обладает более высокой информативностью. Для того чтобы убедиться в этом, рассмотрим многомерное представление данных и сопоставим его с реляционным (рис. 13-14).
Выпуск продуктов цехом по кварталам года
|
Наименование продукта |
Квартал |
Выпуск |
|
Сыр |
I |
20 |
|
Сыр |
II |
30 |
|
Сыр |
III |
25 |
|
Сыр |
IV |
15 |
|
Творог |
I |
20 |
|
Творог |
II |
25 |
|
Масло |
III |
15 |
а) Реляционное представление
Выпуск продуктов цехом по кварталам
|
Наименование продукта |
Выпуск по кварталам |
|||
|
I |
II |
III |
IV |
|
|
Сыр |
20 |
30 |
25 |
15 |
|
Творог |
20 |
25 |
|
|
|
Масло |
|
|
15 |
|
б) Многомерное представление (срез)
Рис. 13. Реляционное и многомерное представление данных
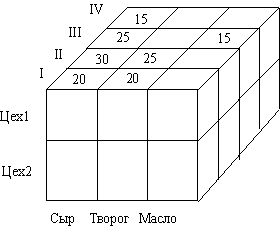
В примере на рис. 14 каждое значение выпуска однозначно определяется комбинацией временного измерения (квартал), названием выпускающего цеха и наименованием товара.
Рис. 14. Пример трехмерной модели
В современных многомерных системах используется обычно два варианта (схемы) организации данных: гиперкубическая и поликубическая. В гиперкубической схеме все показатели определяются одним и тем же набором измерений и даже при наличии нескольких гиперкубов в базе все они имеют одинаковую размерность и совпадающие измерения. При поликубической организации в базе может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. Примером поликубической системы является сервер Oracle Express Server.
Для многомерной модели применяются специальные операции: Срез, Сечение, Вращение, Агрегация, Детализация.
Срез – это подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. Так, в нашем примере можно ограничить значение наименования продукта продуктом Сыр. В этом случае получим срез в виде двумерной таблицы выпуска этого продукта по кварталам года цехами предприятия (рис. 15).
Выпуск сыров цехами по кварталам года
|
Номер цеха |
Квартал I |
Квартал II |
Квартал III |
Квартал IV |
|
Цех 1 |
20 |
30 |
25 |
15 |
|
Цех 2 |
10 |
25 |
30 |
35 |
Рис. 15. Срез многомерной модели
Вращение изменяет порядок измерений при визуальном представлении данных. Вращение применяется обычно при двумерном представлении данных. Так, в примере на рис. 13 вращение приведет к изменению вида таблицы, так, что по оси ОХ будет Наименование продукта, а по оси OY – Выпуск по кварталам (таблица 10).
Таблица 10
|
Кварталы |
Наименование продукта |
||
|
Сыр |
Творог |
Масло |
|
|
I |
20 |
20 |
- |
|
II |
30 |
25 |
- |
|
III |
25 |
- |
15 |
|
IV |
15 |
- |
- |
Операцию вращения можно обобщить и на многомерный случай для изменения порядка следования измерений, например, перестановки местами двух произвольных измерений.
Агрегация и Детализация означают соответственно переход к более общему и более детальному представлению данных. Для понимания сути операции агрегации положим, что имеется гиперкуб, в котором кроме измерений, приведенных на рис. 13, имеются еще подразделение Участок. В этом случае в гиперкубе будет иерархия Цех – Участок. Допустим, в гиперекубе определено, сколько произведено продукции каждым из участков цеха 1. Тогда, поднимаясь на более высокую ступень иерархии, с помощью операции Агрегация можно определить выпуск и для всего цеха 1.
Достоинством многомерной модели является удобство и эффективность анализа больших объемов данных, имеющих временную связь, а также быстрота реализации сложных нерегламентированных запросов. Недостаток этой модели в громоздкости в случае ее использования для решения стандартных задач оперативной обработки. Она, по сравнению с реляционными, не эффективно использует память, так как в ней резервируется место для всех значений, даже если некоторые из них будут отсутствовать (рис. 14). Обычно многомерную модель применяется, когда объем базы не велик и гиперкуб использует стабильный по времени набор измерений.
Многомерные модели поддерживают следующие системы: Essbase (фирма Arbor Software), Media Multi-matrix (фирма Speedware), Oracle Express Server (фирма Oracle), Cache (фирма InterSystems). Некоторые системы поддерживают одновременно реляционную и многомерную модель, например, Media/MR (фирма Speedware).
4.3. Объектно-ориентированная модель данных
Объектно-ориентированная модель представляет структуру, которую можно изобразить графически в виде дерева, узлами которого являются объекты (рис. 16). Между записями базы данных и функциями их обработки устанавливаются связи с помощью механизмов, подобных тем, которые имеются в объектно-ориентированных языках программирования. Такая модель позволяет идентифицировать отдельные записи базы. Определяемый пользователем объект называют объектом-целью. Поиск в объектно-ориентированной базе состоит в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в базе.
Базовыми понятиями этой модели являются следующие: объекты, классы, методы, инкапсуляция, наследование, полиморфизм.
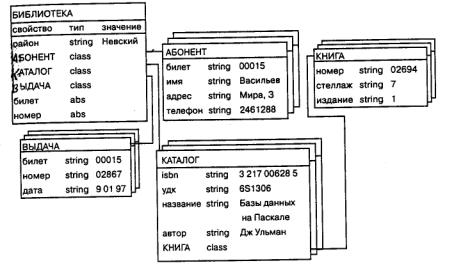
Рис. 16. Объектно-ориентированная база данных
Понятие объекта взято из объектно-ориентированного программирования. В этой среде все состоит из объектов. Объект обладает следующими свойствами: идентифицируется уникальным неизменным образом, принадлежит к определенному классу, может посылать сообщения другим объектам, имеет внутреннее состояние.
Таким образом, объектно-ориентированная база данных состоит из объектов, каждый из которых должен принадлежать к определенному классу, то есть каждый объект – экземпляр класса. Объектно-ориентированная база данных состоит из коллекции классов. Структура и поведение объектов в объектной среде полностью определяется его классом. Класс, в свою очередь, является коллекцией объектов, при этом структура и поведение объектов одного класса одинаковы.
Класс объекта состоит из его интерфейса и закрытой области. Интерфейс класса – это то, что видно другим объектам. Он, в свою очередь, состоит из двух частей: свойства класса и методов класса. Аналогом свойств являются атрибуты отношений. Например, клиент может иметь следующие свойства: номер, ФИО, адрес, телефон. К свойствам относятся также связи с другими объектами. Свойства сами могут быть объектами, что позволяет создавать составные объекты, например, свойство ФИО может состоять из свойств: фамилия, имя, отчество.
Доступ к значениям свойств и манипулирование ими можно осуществлять только посредством методов класса. То есть поведение объекта задается с помощью методов его класса. Обычно они имеют форму операций и функций, которые могут содержать параметры. На уровне интерфейса видимым является только имя каждого метода и требуемые параметры. Методы служат для передачи объектам сообщений. Другими словами, метод представляет то, что, по мнению пользователя, должен делать объект. Например, клиент может сделать заказ, оплатить счет и т.п. Для каждого из этих видов деятельности должен быть соответствующий метод.
Закрытая область – это та часть определения класса, которая не видна другим объектам. Пользователю объекта предоставляется информация только о том, как работать с объектом при помощи его методов. Сама же работа объекта скрыта от пользователя. Например, могут существовать дополнительные свойства с закрытыми значениями, а также скрытые связи и сообщения другим объектам.
Свойства объектов описываются либо одним из стандартных типов, заложенных в системе, например, строковым типом String, либо типом, который конструирует сам пользователь. Этот тип определяется словом Class. Значением свойства типа Class является объект, являющийся экземпляром соответствующего класса. Каждый объект – экземпляр класса считается потомком объекта, в котором он определен как свойство. Объект – экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в базе образуют связанную иерархию объектов.
Важным достоинством объектно-ориентированной базы является то, что пользователю не нужно знать о взаимодействии объектов: он просто обращается к конкретному объекту и использует конкретный метод. А то, что при этом осуществляется воздействие на другие объекты базы, скрыто от пользователя. Различные правила, руководящие использованием объектов, также могут быть скрыты от пользователя. Например, выбранный метод может, в свою очередь, обращаться к другим методам, например, методу проверки кредитоспособности выбранного клиента.
Чтобы определить класс объектов, нужно задать его свойства и методы, а также определить его взаимодействие с другими объектами. Понятие класс объекта во многом аналогично понятию тип. Поэтому при проектировании объектно-ориентированной базы данных нужно, прежде всего, осуществить процесс классификации, то есть выявить объекты с аналогичными свойствами и поведением и объединить их в классы.
Этих действий можно добиться и реляционных базах. Но для этого надо создать специальные приложения, предоставляющие пользователю интерфейс, производящий определенные действия, основанные на работе других частей базы данных. При объектной ориентации подобная деятельность может быть частью определенного объекта, а не представлять собой отдельное приложение. Таким образом, используя объекты и методы, можно хранить и неоднократно использовать не только структуру объекта базы данных, но и его поведение.
Инкапсуляция означает объединение в единое целое данных и алгоритмов (функций и методов) их обработки, а также скрытие данных внутри объектов, что повышает надежность разрабатываемого программного обеспечения. То есть вся информация об объекте заключена в определении его класса. Доступ к объекту может осуществляться только через его интерфейс. Поведение объекта полностью определяется принадлежностью к конкретному классу.
Наследование распространяет множество свойств и методов на всех потомков объекта. Аналогом наследования можно считать разбиение на подтипы. Например, можно определить классы Мужчина и Женщина как наследующие класс Человек. Все эти классы будут иметь общие свойства и методы. Однако в определении новых классов можно добавить дополнительные свойства и методы.
Полиморфизм допускает в объектах разных типов иметь методы (процедуры и функции) с одинаковыми именами, что означает способность одного и того же программного кода работать с разнотипными данными.
Создание объектной модели начинается с классификации – выявлении объектов с аналогичными свойствами и поведением и объединении их в классы. Например, в базе данных, содержащей диаграммы, можно классификацию начать с выделения объектов диаграмм, имеющих дату их создания. Процесс классификации позволяет выделить объекты с общими свойствами и методами. Однако, некоторые их свойства и методы различны. В этом случае производят генерализацию и специализацию.
Генерализация выявляет классы объектов с аналогичными свойствами и образует на основе этих свойств абстрактный суперкласс. Например, в базе данных, содержащей описание геометрических фигур, можно начать проектирование с выделения классов: треугольников, прямоугольников, окружностей, – а затем образовать из них абстрактный суперкласс Фигуры, состоящий из свойств, общих для всех фигур. Специализация – процесс обратный генерализации. При использовании этих процессов создается иерархия классов. Иерархии указывают цепочку наследования.
Важным процессом в объектно-ориентированной базе является агрегация. С помощью агрегации классы объектов могут связываться друг с другом, образуя класс агрегатов. Например, банковская база может содержать информацию о клиентах, счетах, филиалах, а также связи между ними. В объектно-ориентированной базе всю эту информацию можно инкапсулировать в одном агрегированном классе объектов.
Таким образом, создание объектно-ориентированной базы данных основано на процессах: классификации, генерализации, специализации и агрегации, – которые проводятся параллельно.
Резюмируя все вышеизложенное, можно сказать следующее:
§ объектно-ориентированная база данных – это попытка применить идеологию объектно-ориентированного программирования к технологии баз данных;
§ объектно-ориентированная база данных состоит из объектов, причем каждый объект принадлежит к определенному классу;
§ поведение объекта полностью определяется его принадлежностью к определенному классу;
§ процесс проектирования объектно-ориентированной базы основан на выявлении классов объектов.
Основным достоинством объектно-ориентированной модели данных по сравнению с реляционной является возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель позволяет также идентифицировать отдельные записи в базе и определять функции их обработки. Учитывая эти достоинства, сегодня уже некоторые реляционные СУБД дополняют функциями, позволяющими воспользоваться преимуществами объектной технологии.
Подводя итоги, можно сказать следующее. Основной недостаток объектно-ориентированной модели состоит в сложности понимания ее сути и низкой скорости выполнения запросов. В настоящее время объектно-ориентированные базы данных достаточно сложны, и потому их коммерческое использование идет медленно. Но у этих моделей есть потенциал, а, стало быть, и будущее. А потому исследования в области объектной ориентации становятся главным направлением в теории СУБД.
Сегодня уже разработаны и успешно функционируют такие системы управления базами данных как: Iris, Orion и др., – обслуживающие эти модели.
4.4. Объектно-реляционная модель
В связи со значительным усложнением приложений появилась новая модель – расширенная реляционная модель (Extended Relation Data Model –ERDM). Эта модель включила в себя основные достоинства объектно-ориентированной модели и одновременно унаследовала простоту структуры реляционных моделей, и потому стала называться объектно-реляционной моделью данных. В отличие от объектно-ориентированной модели (OODM) объектно-реляционная модель (ERDM) основана на стратегии реляционной модели, в то время как OODM модель основана на объектной стратегии. Исходя из этого, модель ERDM наиболее приспособлена для бизнес-приложений, а модель OODM используется в специальных инженерных и научных приложениях. Некоторые специалисты полагают, что в будущем произойдет слияние OODM и ERDM моделей.
Однако у объектно-реляционной и объектно-ориентированной моделей есть и ряд недостатков, основные из которых следующие:
· отсутствие унифицированной теории, которая есть в реляционных моделях;
· отсутствие формальной методологии проектирования баз данных, как нормализация в реляционных базах;
· отсутствие специальных средств создания запросов;
· отсутствие общих правил определения целостности и др.
|
|
© Минск
БГЭУ, |