|
Технологии
баз данных |
ЛЕКЦИИ
Лекция на тему
Разработчик: к.э.н. Зеневич А.М.
План лекции
1. Эволюция концепций обработки данных
2. Системы удаленной обработки
3. Системы совместного использования файлов
4. Клиент/серверные системы
5. Системы обработки распределенных баз данных
&
4. КЛИЕНТ/СЕРВЕРНЫЕ СИСТЕМЫ
4.1. Клиенты, серверы
Наиболее эффективную работу с централизованной БД обеспечивает архитектура клиент/сервер. В отличие от системы удаленной обработки, в которой имеется только один компьютер, клиент/серверная система состоит из множества компьютеров, объединенных в сеть. Компьютеры называемые клиентами, занимаются обработкой прикладных программ. Компьютеры, называемые серверами, занимаются обработкой БД.
Тип компьютеров, используемых в качестве клиентов может быть разным, это могут быть большие ЭВМ или микрокомпьютеры. Однако, как правило, функции клиентов выполняют почти всегда ПК. В роли сервера может выступать компьютер любого типа, но по экономическим причинам функции сервера чаще всего также выполняют ПК, но имеющие более высокую производительность.
4.2. Клиентские приложения, серверы баз данных
На сервере сети размещается БД и устанавливается мощная серверная СУБД – сервер баз данных. Сервер БД – это программный компонент, обеспечивающий хранение больших объемов информации, ее обработку и представление ее пользователям в сетевом режиме.
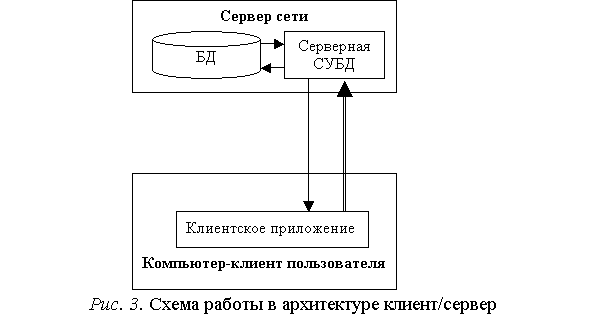
На компьютере-клиенте приложение-клиент формирует запрос к БД. Серверная СУБД обеспечивает интерпретацию запроса, его выполнение, формирование результата запроса и пересылку его по сети на клиентский компьютер. Клиентское приложение интерпретирует его необходимым образом и представляет пользователю. Клиентское приложение может также посылать запрос на обновление БД и серверная СУБД внесет необходимые изменения в БД. Схема архитектуры клиент/сервер приведена на рис. 3.
В архитектуре клиент/сервер функции клиентского приложения и серверной СУБД разделены.
Функции клиентского приложения разбиваются на следующие группы:
· ввод-вывод данных (презентационная логика) – это часть кода клиентского приложения, которая определяет, что пользователь видит на экране, когда работает с приложением;
· бизнес-логика – это часть кода клиентского приложения, которая определяет алгоритм решения конкретных задач приложения;
· обработка данных внутри приложения (логика базы данных) – это часть кода клиентского приложения, которая связывает данные сервера с приложением. Для этой связи используется процедурный язык запросов SQL, с помощью которого осуществляется выборка и модификация данных в серверных СУБД.
Сервер баз данных в общем случае осуществляет целый комплекс действий по управлению данными. Основными среди них являются следующие:
· выполнение пользовательских запросов на выбор и модификацию данных и метаданных, получаемых от клиентских приложений, функционирующих на ПК локальной сети;
· хранение и резервное копирование данных;
· поддержка ссылочной целостности данных согласно определенным в БД правилам;
· обеспечение авторизованного доступа к данным на основе проверки прав и привилегий пользователя;
· протоколирование операций и ведение журнала транзакций.
4.3. Общие сведения о хранимых процедурах и триггерах
В современной модели клиент/сервер бизнес-логика разделена между клиентом и сервером. На сервере бизнес-логика реализована в виде хранимых процедур – специальных программных модулей, которые хранятся в БД и управляются непосредственно СУБД.
Хранимая процедура – это специальная процедура, которая выполняется сервером баз данных. Хранимые процедуры пишутся на процедурном языке, который зависит от конкретной СУБД. Для написания хранимых процедур для MS SQL Server используется расширенный стандарт языка SQL – Transact-SQL. Хранимая процедура здесь – это последовательность операторов Transact-SQL, хранящихся в БД. Хранимые процедуры предварительно откомпилированы, поэтому их эффективность выше, чем обычных запросов. Они выполняются непосредственно на сервере.
Существует два вида хранимых процедур: системные и пользовательские. Системные хранимые процедуры предназначены для получения информации из системных таблиц и выполнения различных служебных операций и особенно полезны при администрировании базы данных. Пользовательские хранимые процедуры создаются непосредственно разработчиками или администраторами базы данных. Полезность хранимых процедур определяется в первую очередь высокой (по сравнению с обычными Transact-SQL запросами) скоростью их выполнения. Однако наибольший эффект достигается при выполнении многократно повторяющихся операций. Пользовательские хранимые процедуры применяются при решении практически любых задач. Пользователь может получить право выполнения хранимой процедуры, даже если он не имеет права доступа к объектам, к которым обращается программа.
Хранимая процедура вызывается явно, т.е. при непосредственном обращении к процедуре из клиентского приложения, работающего с базой данных. Хранимые процедуры используются для извлечения или изменения данных в любое время. Хранимые процедуры могут принимать аргументы при запуске и возвращать значения в виде результирующих наборов данных.
Логика БД реализуется с помощью триггеров. Триггер – это специальный тип хранимой процедуры, которая автоматически выполняется при каждой попытке изменить данные. Триггер всегда связан с конкретной таблицей и выполняется тогда, когда при редактировании этой таблицы наступает событие, с которым он связан (например, вставка, удаление или обновление записи). Каждая таблица может иметь произвольное количество триггеров любых типов. После операций вставки, обновления, удаления может быть запущен триггер, который в результате приведет к вычислению бизнес-правил или к выполнению определенных действий. При удалении таблицы, имеющей триггеры, все они также удаляются.
Триггеры обеспечивают целостность данных, предотвращая их несанкционированное или неправильное изменение. Триггеры не принимают параметров и не возвращают значений. Они выполняются неявно, то есть триггер запускается только при попытке изменения данных. Триггеры могут иметь несколько уровней вложенности (например, в СУБД MS SQL Server триггеры имеют до 32 уровней вложенности), то есть выполнение одного триггера инициирует выполнение другого триггера. Триггер является частью транзакции, следовательно, если триггер не выполнятся, то отменяется вся транзакция. И наоборот, если какая-то часть транзакции не выполнилась, то и триггер будет отменен.
4.4. Преимущества архитектуры клиент/сервер
При клиент/серверной обработке уменьшается сетевой трафик, так как через сеть передаются только результаты запросов.
Груз файловых операций ложится в основном на сервер, который мощнее компьютеров-клиентов и поэтому способен быстрее обслуживать запросы. Как следствие этого, уменьшается потребность клиентских приложений в оперативной памяти.
Поскольку серверы способны хранить большое количество данных, то на компьютерах-клиентах освобождается значительный объем дискового пространства для других приложений.
Повышается уровень непротиворечивости данных и существенно повышается степень безопасности БД, так как правила целостности данных определяются в серверной СУБД и являются едиными для всех приложений, использующих эту БД.
Имеется возможность хранения бизнес-правил (например, правил ссылочной целостности или ограничений на значения данных) на сервере, что позволяет избежать дублирования кода в различных клиентских приложениях, использующих общую базу данных.
4.5. Характеристика серверов баз данных
Современные серверные СУБД:
· существуют в нескольких версиях для различных платформ, как правило, для различных коммерческих версий UNIX – Solaris, HP/UX. Многие производители также выпускают версии своих серверов баз данных для Windows NT Workstation Windows 95/98, а также версии для Linux;
· в большинстве случаев поставляются с удобными административными утилитами;
· осуществляют резервное копирование и архивацию данных и журналов транзакций;
· поддерживают несколько сценариев репликаций;
· позволяют осуществлять параллельную обработку данных в многопроцессорных системах. Серверы, допускающие параллельную обработку, разрешают нескольким процессорам обращаться к одной БД, что обеспечивает высокую скорость обработки транзакций;
· поддерживают создание хранилищ данных и OLAP. Хранилище данных – это совокупность данных, полученных прямо или косвенно их информационных систем, которые содержат текущую и деловую информацию, а также из некоторых внешних источников.
· выполняют распределенные запросы и транзакции;
· дают возможность использовать различные средства проектирования схем данных – универсальные или ориентированные на конкретную СУБД;
· имеют средства разработки клиентских приложений и генераторы отчетов;
· поддерживают публикацию баз данных в Интернет;
· обладают широкими возможностями управления пользовательскими привилегиями и правами доступа к различным объектам БД.
К современным серверам баз данных относятся Oracle 9 (Oracle), MS SQL Server 2000 (MS), Informix (Informix), Sybase (Sybase), Db2 (IBM). Краткий обзор серверных СУБД приведен в пособии [2].
4.6. Механизмы доступа к базам данных
Все серверные СУБД имеют клиентскую часть, которая обращается к БД посредством СУБД. Между клиентским приложением и СУБД не существует прямой связи и дополнительно встраиваются программные модули, позволяющие клиентскому приложению получать доступ к БД, создаваемым с помощью разных СУБД. Такие модули называются механизмами доступа к данным.
Существует два основных способа доступа к данным из клиентских приложений: использование прикладного интерфейса и использование универсального программного интерфейса.
Прикладной программный интерфейс (API – Application Programming Interface) представляет собой набор функций, вызываемых из клиентского приложения. Он может работать только с СУБД данного производителя и при ее замене придется переписывать значительную часть кода клиентского приложения. Прикладной программный интерфейс различен для разных СУБД.
Универсальный механизм доступа к данным обеспечивает возможность использования одного и того же интерфейса для доступа к разным типам СУБД. Обычно он реализован в виде специальных дополнительных модулей, называемых драйверами.
Наиболее распространенным программным интерфейсом, обеспечивающим доступ к данным конкретной базы данных является ODBC (Open Database Connectivity) фирмы Microsoft. В рамках ODBC программное приложение непосредственно взаимодействует с диспетчером драйвером, посылая ему ODBC-вызовы. Диспетчер драйверов отвечает за динамическую загрузку нужного ODBC-драйвера, через который обращается с серверу баз данных. ODBC-драйвер выполняет все вызовы ODBC-функций и «переводит» их на язык источника данных. СУБД хранит и выводит данные в ответ на запросы со стороны ODBC-драйвера.
Задание ODBC-источникаданных является действием, которое осуществляется средствами операционной системы, управляющей компьютером.В операционной системе Windows в Панели управления предусмотрен пункт Исочники данных ODBC (32 разр) из которого вызывается Администратор источников данных ODBC. С его помощью могут быть заданы:
· пользовательский DSN – источник данных, доступный только текущему пользователю на текущем компьютере;
· файловый DSN – источник данных, которые могут применять совместно различные пользователи, у которых установлены одинаковые ODBC-драйверы;
· системный DSN – источник данных, доступный всем пользователям и службам текущего компьютера.
|
|
©
Минск БГЭУ, |